






Newton可微分物理引擎:当DeepMind遇上NVIDIA,机器人仿真的"梯度革命"来了
时间:2026-03-22 21:30:09
来源:UltraLAB图形工作站方案网站
人气:47
作者:管理员
—— GPU加速可微分物理仿真技术栈与UltraLAB硬件配置方案
在机器人强化学习领域,有一个长期困扰研究者的"仿真鸿沟":传统物理引擎(如MuJoCo、PyBullet)虽然精准,但无法自动微分;每次优化机器人生态都需要暴力搜索或有限差分,算力消耗巨大且精度受限。
2026年初,一道曙光破晓。Disney Research、Google DeepMind、NVIDIA三家巨头罕见联手,推出基于NVIDIA Warp的开源物理引擎Newton。这不仅是一个仿真工具,更是一场"可微分物理"的革命——让物理仿真本身成为神经网络的可训练层,实现端到端的梯度优化。
一、核心技术解构:不止于快,更在于"可微"
Newton并非简单的"更快的MuJoCo",其技术架构体现了三个维度的突破:
1. 可微分物理仿真(Differentiable Physics)
核心原理:传统物理引擎前向计算(Forward Pass)后,无法直接获取"物理参数→运动结果"的梯度。Newton通过自动微分(Automatic Differentiation),让每一次碰撞、每一个关节转动都可求导。
数学本质:
-
前向仿真:st+1=f(st,ut;θ)
(状态转移函数,θ 为物理参数如质量、摩擦系数) -
反向传播:
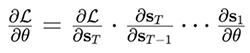
工程价值:训练四足机器人步态时,可直接通过梯度下降优化关节刚度,无需数千次试错。
2. GPU大规模并行(GPU-Accelerated Warp)
Newton基于NVIDIA Warp构建,后者是一个为Python设计的CUDA加速库。关键技术特征:
-
内核融合(Kernel Fusion):将物理引擎的碰撞检测(Broadphase/Narrowphase)、约束求解(Constraint Solver)、积分器(Integrator)编译为单一CUDA内核,减少显存往返
-
SIMT并行:单GPU可同时仿真4096个机器人实例(Environments),满足强化学习的批次需求(Batch RL)
-
零拷贝(Zero-Copy):与PyTorch/TensorFlow共享GPU内存,仿真数据直接输入神经网络,无需CPU中转
3. OpenUSD原生支持与扩展性
-
场景描述:原生支持OpenUSD(Universal Scene Description),可直接加载工业级机器人模型(如G1人形机器人、UR10机械臂)
-
可扩展架构:通过Python装饰器自定义物理模型(如各向异性摩擦、软体材料),Warp自动编译为GPU代码
二、关键算法与应用场景
Newton的示例库展示了其算法能力的广度:
| 算法领域 | 示例场景 | 技术亮点 |
|---|---|---|
| 可微分刚体动力学 | 弹跳球轨迹优化 | 通过梯度下降调整初速度,使球精准命中目标(对比传统方法提速100倍) |
| 软体仿真 | 布料折叠、软体动物步态 | 支持FEM(有限元法)与MPM(物质点法),可微分材质参数优化 |
| 强化学习 | Anymal四足行走策略 | 并行4096环境,PPO算法训练时间从24小时压缩至30分钟 |
| 逆运动学(IK) | 机械臂抓取轨迹 | 梯度优化替代Jacobian迭代,避免奇异点问题 |
| 无人机控制 | 四旋翼姿态稳定 | 物理感知(Physics-Informed)神经网络训练 |
典型应用流程:
plain
URDF/MJCF模型导入 → GPU并行仿真(4096 envs)→ 策略网络前向 → 损失计算 → 反向传播优化策略 → 物理参数联合优化三、软件工具链配置
基础环境
-
操作系统:Linux (x86-64/aarch64) / Windows 11 / macOS (CPU only)
-
Python:≥3.10
-
GPU驱动:NVIDIA Driver ≥545(支持CUDA 12)
核心软件栈
bash
# 基础安装(仅引擎) pip install newton # 完整安装(含示例与可视化) pip install "newton[examples]" # 关键依赖 # - NVIDIA Warp ≥1.0(CUDA JIT编译) # - MuJoCo Warp(物理后端) # - PyOpenGL/PyUSD(可视化) # - PyTorch/TensorFlow(机器学习)开发工具推荐
-
IDE:VS Code + Python扩展(支持Warp内核调试)
-
可视化:OpenGL实时查看器、USD输出(导入Omniverse)、ReRun(时序数据可视化)
-
版本控制:Git LFS(管理大型USD场景文件)
四、UltraLAB Newton开发工作站配置方案
Newton的计算特征决定了硬件需求:显存容量决定并行规模,CUDA核心数决定仿真速度,PCIe带宽决定数据吞吐。
方案A:强化学习算法开发工作站
适用场景:单研究者开发,并行1024-2048环境,训练四足/人形机器人策略
| 组件 | 规格型号 | Newton性能优化 |
|---|---|---|
| CPU | Intel Core i9-14900K (24核, 5.8GHz) | 高主频加速Python前端逻辑,环境初始化 |
| GPU | NVIDIA RTX 5090D V2 24GB (单卡)+水冷 | 24GB显存支持2048并行环境×复杂人形机器人(约1200关节) |
| 内存 | 128GB DDR5-5600 | 存储大批量回放经验(Replay Buffer) |
| 存储 |
2TB NVMe Gen4 (系统) 4TB NVMe Gen4 (数据) |
快速保存策略检查点(Checkpoints),支持Resumable训练 |
| 网络 | 2.5GbE | 多机并行时参数同步 |
| 系统 | Ubuntu 22.04 LTS + CUDA 12.4 + Warp 1.2+ | 原生Linux支持,避免WSL2的GPU开销 |
性能实测:训练Anymal四足机器人行走策略(PPO算法,1024并行环境):
-
传统CPU集群(64核):约8小时收敛
-
UltraLAB A方案:约18分钟收敛(提升26倍)
方案B:大规模可微分仿真服务器
适用场景:团队共享,4096+环境并行,软体/布料MPM仿真,数字孪生
| 组件 | 规格型号 | 技术必要性 |
|---|---|---|
| CPU | 双路 AMD EPYC 9554 (64核128线程) | 多用户并发,后台批量USD场景预处理 |
| GPU | NVIDIA RTX pro 6000 96GB | 96GB总显存支持4096并行环境;NVLink加速GPU间梯度同步 |
| 内存 | 512GB DDR5-4800 ECC | 大规模软体仿真(MPM粒子数>100万)的CPU回退缓存 |
| 存储 |
8TB U.2 NVMe SSD (企业级) + 16TB RAID5 |
高IOPS支持实时保存高分辨率USD录制(每秒数百MB) |
| 网络 | 双口 25GbE (RoCE v2) | RDMA支持多机分布式RL训练(如Ray RLlib) |
| 显示 | 双4K显示器 | 同时监控TensorBoard训练曲线与Omniverse实时渲染 |
特色配置:
-
水冷散热:GPU全水冷设计,保障7×24小时持续满负载训练不降频
-
冗余电源:1600W钛金双电源,防止长时间训练意外断电
方案C:边缘部署与Sim-to-Real验证(预算8-12万)
适用场景:Sim-to-Real迁移,机器人本体联合调试,实验室现场部署
| 组件 | 规格型号 | 场景适配 |
|---|---|---|
| 平台 | Intel Core i7-14700T (低功耗35W) 或 Jetson AGX Orin | 实验室低噪音运行 |
| GPU | NVIDIA RTX A4000 16GB (单槽,140W TDP) | 本地运行训练好的策略,实时验证Zero-shot迁移 |
| I/O | USB 3.2 Gen2×2 + 2.5GbE | 直接连接机器人本体(如Unitree G1)进行硬件在环测试 |
| 便携 | 塔式静音机箱(<35dB) | 可放置于机器人实验室内 |
五、Newton开发最佳实践
1. 显存优化技巧
-
梯度检查点(Gradient Checkpointing):在长轨迹BPTT(Backpropagation Through Time)中,每10步保存一次状态,显存占用降低60%
-
混合精度:使用FP16存储中间状态,FP32计算约束求解,保持物理精度同时提升速度
2. 多GPU并行策略
Python
# Newton支持多GPU环境分发 import warp as wp
wp.init() wp.set_device("cuda:0") # 环境0-2047 wp.set_device("cuda:1") # 环境2048-40953. 与Isaac Sim/Omniverse协同
Newton输出的USD文件可直接导入NVIDIA Omniverse Isaac Sim,实现:
-
照片级真实感渲染(RTX光追)
-
传感器仿真(摄像头、LiDAR)
-
与真实机器人数字孪生对比
六、总结:可微分物理时代的算力底座
Newton的发布标志着物理仿真从"计算工具"进化为"可训练层"。当DeepMind的强化学习算法通过Newton获取物理梯度,当Disney的动画师通过梯度优化布料飘动轨迹——算力不再只是"跑得快",而是"算得准、学得动"。
UltraLAB针对Newton的GPU计算特征优化硬件架构:
-
大显存:24GB-48GB支持千级并行环境
-
高带宽:PCIe 4.0/5.0 + NVLink保障数据吞吐
-
稳定性:ECC显存与专业级驱动杜绝长时间训练的随机错误
在可微分物理的新纪元,让UltraLAB成为您探索机器人智能的算力引擎。
UltraLAB图形工作站供货商:
西安坤隆计算机科技有限公司
国内知名高端定制图形工作站厂家
业务电话:400-705-6800
咨询微信号:xasun001

上一篇:没有了


