






7B小模型干翻32B!SWE-Protégé本地化部署指南:如何用一台工作站打造AI编程团队
时间:2026-03-23 08:05:03
来源:UltraLAB图形工作站方案网站
人气:36
作者:管理员
"一个人加一台工作站,就能拥有媲美32B大模型的代码修复能力?"
2026年2月,Meta联合密歇根大学、斯坦福大学发布的SWE-Protégé框架,让这个设想成为现实。通过创新的"专家-门徒"协作范式,仅需7B参数的小模型就能在SWE-bench Verified上达到42.4%的解决率,不仅超越32B开源模型SOTA,更让单任务成本直降8.2倍。
对于软件研发团队、独立开发者和AI创业公司而言,这意味着:本地化部署的智能编程Agent不再是幻想。
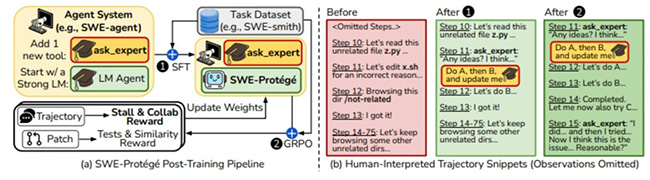
一、SWE-Protégé核心技术解析
1. 范式革新:从"单打独斗"到"师徒协作"
传统软件工程Agent依赖单一模型端到端执行,而SWE-Protégé重构了协作逻辑:
-
门徒(Protégé):7B小语言模型(如Qwen2.5-Coder-7B)作为唯一执行者,负责代码浏览、工具调用、代码修改等90%的常规工作
-
专家(Expert):Claude等大模型作为战术顾问,仅在任务陷入停滞时被动调用,提供高维度指导
核心优势:专家Token占比仅11%,绝大多数推理在本地完成,既保障数据安全,又实现成本可控。
2. 两阶段训练框架
| 阶段 | 技术方法 | 训练目标 |
|---|---|---|
| 阶段一:SFT | 监督微调 | 教会模型"如何与专家协作"——调用时机、上下文组织、建议落地 |
| 阶段二:GRPO | 在线强化学习 | 教会模型"何时求助"——通过循环抑制奖励和协作质量奖励,根治退化动作循环 |
3. 行为根治:从"死循环"到"高效协作"
传统小模型在长周期任务中极易陷入退化动作循环(反复执行grep、view等无效命令)。SWE-Protégé通过定制化复合奖励函数:
-
循环抑制阶段:强惩罚无效循环,迫使模型在卡住时主动求助
-
协作质量优化:专家模型作为裁判,评估求助合理性与建议落地度
效果:超过20步的长循环从31%降至0.8%,比Claude Sonnet本身(1.8%)更低。
二、本地部署安装指南
环境准备
系统要求:
-
Ubuntu 22.04 LTS 或 WSL2(Windows)
-
Python 3.10+
-
CUDA 12.1+(用于本地GPU推理)
-
Docker(用于SWE-agent沙箱环境)
依赖安装:
bash
# 1. 创建虚拟环境 conda create -n swe-protege python=3.10 conda activate swe-protege # 2. 安装SWE-agent基础环境 git clone https://github.com/princeton-nlp/SWE-agent.git cd SWE-agent
pip install -e . # 3. 安装SWE-Protégé框架(基于官方实现) git clone https://github.com/meta-research/swe-protege.git cd swe-protege
pip install -r requirements.txt # 4. 安装vLLM用于本地模型推理(推荐) pip install vllm==0.4.2模型准备与配置
步骤1:下载门徒模型(7B小模型)
bash
# 使用Hugging Face下载Qwen2.5-Coder-7B-Instruct huggingface-cli download Qwen/Qwen2.5-Coder-7B-Instruct --local-dir ./models/protege-7b # 如需使用SWE-Protégé训练后的权重(性能更优) huggingface-cli download meta-research/swe-protege-7b --local-dir ./models/swe-protege-7b
步骤2:配置专家模型API
bash
# 编辑配置文件 config.yaml cat > config.yaml << EOF
protege:
model_path: "./models/swe-protege-7b"
tensor_parallel_size: 1 # 根据GPU数量调整
gpu_memory_utilization: 0.9
expert:
provider: "anthropic" # 或 "openai"
model: "claude-3-7-sonnet-20250219"
api_key: "$ANTHROPIC_API_KEY"
max_tokens_per_task: 4000 # 限制专家Token消耗
grpo:
enable: false # 部署阶段关闭训练,仅推理
temperature: 0.2
swe_agent:
environment: "docker"
container_name: "swe-sandbox"
timeout: 300 # 单任务超时时间(秒)
EOF
步骤3:启动本地推理服务
bash
# 启动vLLM服务(后台运行) python -m vllm.entrypoints.openai.api_server \ --model ./models/swe-protege-7b \ --tensor-parallel-size 1 \ --gpu-memory-utilization 0.9 \ --max-model-len 32768 \ --port 8000 & # 验证服务 curl http://localhost:8000/v1/models
步骤4:运行SWE-Protégé任务
bash
# 单任务测试(以SWE-bench示例为例) python run_protege.py \ --config config.yaml \ --instance_path test_instance.json \ --output_dir ./results # 批量评估 python evaluate.py \ --dataset swe-bench-verified \ --split test \ --max_workers 4 \ --output results.json关键配置优化
内存优化(针对长代码仓库):
Python
# 在config.yaml中添加 context_management: max_context_tokens: 16000 # 控制上下文长度 summarization_threshold: 12000 # 超长时自动摘要 file_cache_size: 100 # 缓存最近浏览的100个文件
专家调用策略:
yaml
expert_calling: strategy: "adaptive" # 自适应调用 stall_threshold: 5 # 连续5步无进展则触发专家 max_calls_per_task: 8 # 单任务最多调用8次专家 early_exit: true # 任务解决后立即停止三、配套硬件配置推荐
SWE-Protégé的部署对硬件有明确要求:7B门徒模型需本地GPU推理,代码仓库解析需要大内存,专家API调用需要稳定网络。
配置方案A:个人开发者入门版(单卡推理)
适用场景:个人开发者、小型项目代码审查、编程学习辅助
| 组件 | 推荐配置 | 说明 |
|---|---|---|
| CPU | Intel Core i9-14900K / AMD Ryzen 9 7950X3D | 高频多核,加速代码索引构建 |
| GPU | RTX 4090 24GB ×1 | 7B模型推理舒适区,支持32K上下文 |
| 内存 | 64GB DDR5-5600 | 同时运行Docker沙箱+IDE+浏览器 |
| 存储 | 2TB NVMe Gen4 (系统+模型) + 8TB HDD (代码库) | 快速加载模型,大容量存储多项目 |
| 网络 | 千兆以太网 | 稳定调用Claude/OpenAI API |
参考机型:UltraLAB A330
-
预估并发:单任务处理,响应延迟<2秒/步
-
日处理能力:约50-80个中等复杂度Issue
配置方案B:专业开发团队版(双卡加速)
适用场景:技术团队代码审查、自动化Bug修复、CI/CD集成
| 组件 | 推荐配置 | 说明 |
|---|---|---|
| CPU | AMD Threadripper 7970X (32核) | 多线程并行处理多个代码仓库 |
| GPU | RTX 4090 48GB | 支持并发任务或更大上下文 |
| 内存 | 128GB DDR5-4800 ECC | 支持同时分析多个大型代码库(如Linux内核级) |
| 存储 | 4TB NVMe Gen4 RAID0 (高速) + 20TB NAS | 快速I/O处理高频文件访问 |
| 网络 | 10GbE + 双WAN | 保障API调用稳定性,避免专家请求超时 |
参考机型:UltraLAB AR450
-
预估并发:4-6个任务并行处理
-
日处理能力:约200-300个Issue,支持团队级Code Review自动化
配置方案C:企业级研发平台(多机集群)
适用场景:大型企业代码库维护、跨项目Bug修复、AI辅助研发中台
表格
| 组件 | 推荐配置 | 说明 |
|---|---|---|
| CPU | 2× AMD EPYC 9654 (192核) | 超大规模并行,支持百级并发 |
| GPU | RTX A6000 48GB ×4 / A100 80GB ×2 | 支持更大模型(14B+)或批量推理 |
| 内存 | 512GB DDR5 ECC | 内存级缓存超大代码仓库 |
| 存储 | 20TB NVMe全闪存阵列 | PB级代码数据实时检索 |
| 网络 | 25GbE InfiniBand | 集群内高速通信,低延迟API聚合 |
参考机型:UltraLAB WS850R (4GPU机架式)
-
预估并发:20+任务并行
-
特色功能:支持模型微调(继续训练专属门徒模型)
四、部署效益分析
成本对比(以月处理1000个Issue计)
| 方案 | 硬件投入 | API成本/月 | 总成本/月 | 数据安全 |
|---|---|---|---|---|
| 纯云端32B模型 | 无 | ¥15,000+ | ¥15,000+ | 代码外泄风险 |
| SWE-Protégé方案 | ¥25,000(一次性) | ¥2,000 | ¥2,000 | 本地执行,仅元数据上云 |
| 节省比例 | - | 87% | 87% | 显著提升 |
性能表现
-
解决率:42.4%(SWE-bench Verified),超越GPT-4早期版本
-
响应速度:本地7B模型推理延迟<500ms,整体任务完成时间平均15分钟
-
专家依赖度:仅11%的Token调用专家,即使断网也能完成基础代码浏览
五、结语:AI编程的新范式
SWE-Protégé证明了一个趋势:未来的AI应用不是"大模型通吃一切",而是"小模型主导+大模型顾问"的协作模式。
对于软件研发团队而言,这意味着:
-
成本可控:无需昂贵的云端大模型订阅
-
数据安全:核心代码始终留在本地
-
效率倍增:7×24小时自动化的代码审查与修复
UltraLAB图形工作站为SWE-Protégé提供从入门到企业级的完整算力支撑。无论您是独立开发者还是技术团队,我们都能为您提供匹配的生产力装备。
下一步:访问我们的技术顾问团队,获取针对您代码库规模的定制化部署方案。
参考资源:
-
SWE-agent官方仓库:https://github.com/princeton-nlp/SWE-agent
UltraLAB图形工作站供货商:
西安坤隆计算机科技有限公司
国内知名高端定制图形工作站厂家
业务电话:400-705-6800
咨询微信号:xasun001



