






2880流处理器!NVIDIA GK110详细解读
泡泡网显卡频道5月19日 首日的GTC 2012大会上,NVIDIA CEO黄仁勋就为我们正式介绍了全息Kepler架构的GK110 GPU,产品将被应用在Tesla K20 GPU计算卡上,相比Fermi提供3倍的双精度浮点计算性能。

GK110采用28nm工艺,拥有71亿晶体管,按照GK104的294mm2来计算应该达到了550mm2+的水准,同GF110一样,GK110同样是为双精度浮点计算而设计的计算卡,虽然规格达到了两倍的GK104,但是游戏性能提升将打一部分折扣,GK110单/双精度浮点计算按照1/3设计,对比GK104则为1/24,很明显是为游戏而设计的。

基于GK110的Tesla K20 GPU计算卡
而在高性能计算领域,GK110也是首款支持Hyper-Q、Dynamic Parallelism并行调度的GPU,这也是NVIDIA将其计算定位3.5代的原因,相比GK104有了显著的改善。
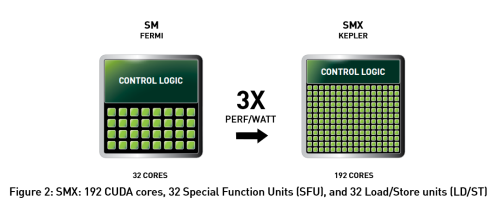
规格方面GK110 71亿晶体管主要用于CUDA核心、以及显存控制器的增加,SMX流式多处理器增加到15组,每组继续保持GK104的192 CUDA设计架构,也就是GK110总计拥有多达2880个流处理器(CUDA)。
GK110和GK104二者的架构还是有所区别,为了增加双精度计算能力,GK110每组SMX提供多达64个FMA双精度单元,对比GK104只有8个FMA双精度单元,这也是二者在双精度计算能力上巨大差距的原因。

GK110 Die
按照NVIDIA的数据GK104的单双精度计算能力分别为3.09TFLOPS和0.13TFLOPS,而GK110单双精度计算能力分别达到了4.2TFLOPS和1.4TFLOPS,分别提升了36%和1077%。

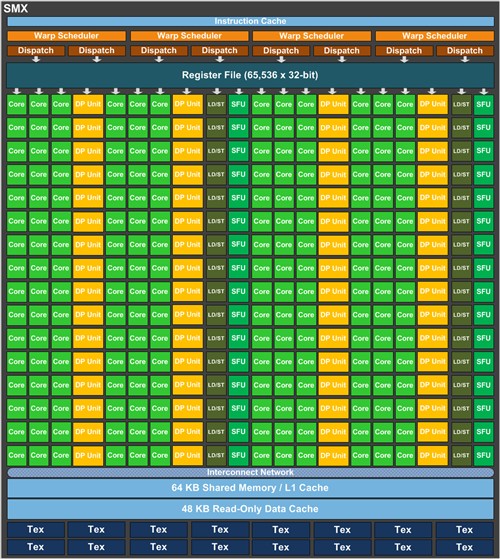
GK110 SMX
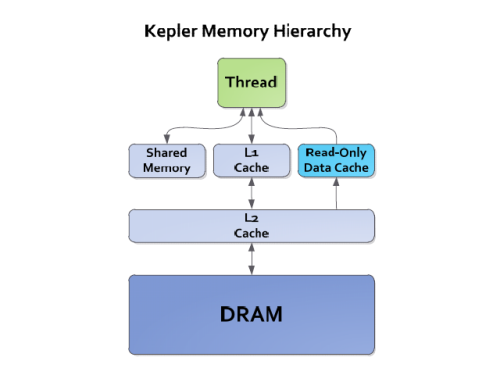
为满足带宽传输需求,GK110提供了六组GDDR5显存控制器,组成384Bit显存位宽,显存带宽提升至256GB/s。而15组SMX流式多处理器共享的L2缓存也翻倍至1.5MB(对比Fermi为768KB),并具备ECC片上保护,线程只能单向调用L2缓存(或者通过L1->L2逐级调用),并不具备写入L2的权限。
频率方面,GK110核心并不会像GK104冲破1GHz,作为计算卡,GK110会保守的设置在800MHz左右,尽管如此,GK110的功耗还是得到了显著地提升,功耗应该在260-300W之间的水平,需配备6pin+8pin PCI-E供电接口才能够满足。

已经完善的GTX 600高端系列产品线
而在桌面推广上,GK110很大可能将会为下一代GeForce GTX 780而准备,由于架构设计原因,玩家们期待的游戏性能将不足以推翻现有的GTX 690显卡,不过更好的散热控制,另外相对GTX 680不错的性能提升,还是可以胜任下一代显卡的需求。
Quad Warp调度和Dynamic Parallelism解析
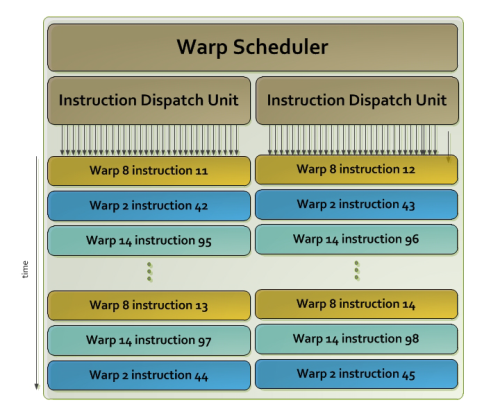
● Quad Warp Scheduler调度
在SMX流式多处理器中,每32并行线程叫做为warps,而每个SMX中拥有四组Warp Scheduler调度和八组instruction dispatch单元,允许四个warps同时执行,而Kepler的Quad Warp Scheduler调度正是基于四组warps,在每个循环中可以指派2个独立的指令,不同于Fermi,GK110允许双精度指令和部分其他指令配对,例如load/store、texture以及一些整数型指令,以提高效率。
在采样和图像数据过滤,GPU硬件纹理单元显得非常重要,相对Fermi,Kepler的纹理吞吐量得到急剧增加,每组SMX中包含了16个纹理填充单元,对比Fermi GPU(GF110)增加了4倍。
● Dynamic Parallelism
在混合CPU-GPU系统中,较大的并行代码在GPU内被完整执行可有有效提升GPU的性能和效能,而目前来说GPU并不具备完全处理这样的并行任务,需要大量利用到CPU来参与计算处理,kernel的创建都需要CPU来实现,严重影响了GPU的计算执行效率。
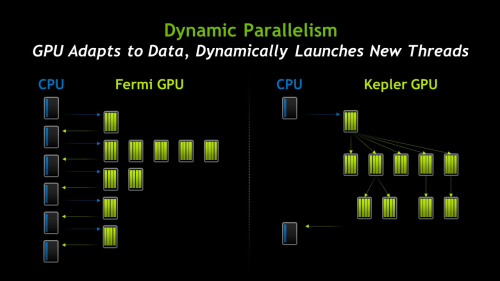
而为了让GPU更大限度的发挥并行计算的能力,GK110引入了Dynamic Parallelism(动态并行调度),使得GPU内核有了独立载入工作负载的能力,G能够在GPU片上自身对kernel执行后的结果进行判断并确定、创建后续新的kernel。 #p#page_title#e#
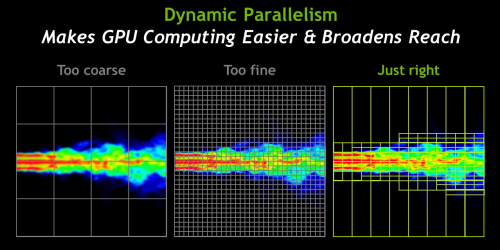
使用Dynamic Parallelism将大大简化了并行编程,让GPU加速能够应用到更广范围的流行算法上,例如自适应网格细分、高速多级法以及多栅法。
Hyper-Q和Grid Management Unit解析
● Hyper-Q
在Fermi时代,CPU只能够同时运行1个MPI(Message Passing Interface)任务,而Kepler GK110可以实现同时32个MPI的任务执行,Hyper-Q让多个CPU核心能够同时利用单个Kepler GPU上的诸多CUDA核心。大大提升了GPU的利用率、缩短了CPU闲置时间、提高了可编程性。Hyper-Q非常适合采用MPI的集群应用程序。

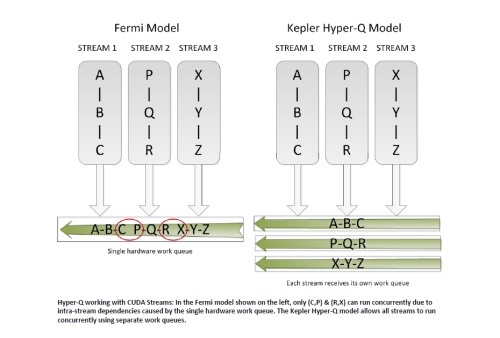
Hyper-Q的显著改善在于使用MPI的并行计算系统,基于早期MPI系统算法的多核CPU系统的负载低于GPU的实际能力,导致GPU资源并不能被充分利用,GPU并没有分配到足够的工作,出现了虚假的瓶颈依赖,Hyper-Q将移除这些虚假依赖,大大提高了整个MPI进程的GPU共享效率。
● Grid Management Unit
在Fermi时代,CWD(CUDA Work Distributor)下Grid进入GPU内执行后,必须等到工作完全执行完后才能运行另一个Grid,而在GK110中,工作流程中加入了全新的Grid Management Unit管理单元,由CWD发射的Grid首先将进入Grid Management Unit管理单元。
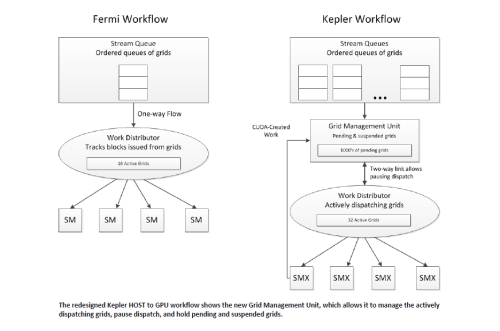
Grid Management Unit能够智能管理CUDA创建的、CPU建立的gird,可以实现暂停新grid的分发、停掉申请的gird、挂起的grid,直到再需要它们的时候。SMX和Grid Management Unit有专门的直连连接,从而可以核准在GPU上透过名为Dynamic Parallelism的技术将新工作发送回Grid Management Unit来排序和分发。
● NVIDIA GPUDirect
面对大量数据,增加数据吞吐量和降低延迟是增加计算性能的关键,GK110支持NVIDIA GPUDirect的RDMA,允许第三方直接访问GPU显存,例如IB适配器、NIC(网卡)和SSD,使用NVIDIA最新的CUDA 5.0,GPUDirect可以提供如下新特性:
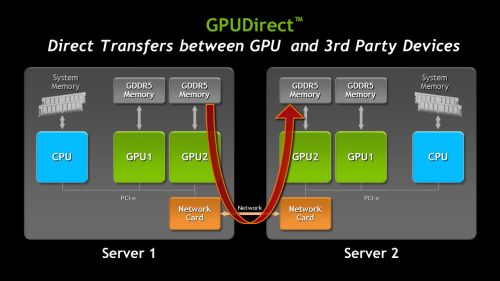
- NIC和GPU之间无需CPU端数据缓冲的直接内存访问(DMA)
- 显著改善MPISend/ MPIRecv GPU和其他网络节点之间的效率
- 消除CPU带宽和延迟瓶颈
- 与大量第三方设备(采集、存储设备)协同工作

例如在石油和天然气勘探地震成像跨多个GPU的影像数据处理上,以往需要数以百计的CPU参与紧密合作,改用GPUDirect后,将直接改善多个GPU的影像数据的协同处理,CPU参与数据沟通的工作将得到全面缓解


